Machine Learning (concepts) 101
A few weeks ago I started seriously studying Machine Learning (ML). I have taken some courses and read some books before, but now I am taking a step ahead. I do plan to start working on ML projects and really get into the field.
To me, the only way to make sure you understand something, is the fact that you are able to explain it to others. Because of this, I decided to write a Machine Learning 101 blog post, in which I explain some (very) basic ML concepts. The idea is to write something I can reference in future, more project-based blog posts. Let’s begin.
What is Machine Learning
It is very easy to get confused with all the terms: Artificial Intelligence,
Machine Learning, Data Science, Deep Learning, etc. People tend to use any of those
terms to talk about… anything?! The truth is that all of them talk about the same idea.
Or at least it is how I perceive it. The main idea is, to me:
Machine Learning is about giving computers the ability to learn from data
Here is a really good post if you want to know more about the differences in those terms.
How does a machine… learn?
If we want computers to be able to learn from data, we need to provide them with… well, data. When you hear or read something about “training an algorithm” what it means is that you’re feeding an algorithm with data.
This data needs to be converted to vectors of “features”, which are almost always represented as numbers. This data can be labeled or not, and depending on the case we are talking about two different types of “learning”.
Supervised Learning
When the data is labeled, meaning that we know stuff about the data, we are talking about supervised learning. An example would be a list of clinical samples with a label saying if the patient had cancer or not. The data we feed the algorithm with is usually called a training set. Supervised learning focuses mainly in classification and prediction tasks.
As a very silly example, suppose we have a data file that contains a list of students. For each student, we have the number of hours studied in a subject and the average grade obtained having studied those hours. Something like this:
| Student | Hours studied | Grade |
|---|---|---|
| Jon | 3 | 4.4 |
| Doe | 7 | 6.4 |
| … | … | … |
We could represent this data in a scatter plot
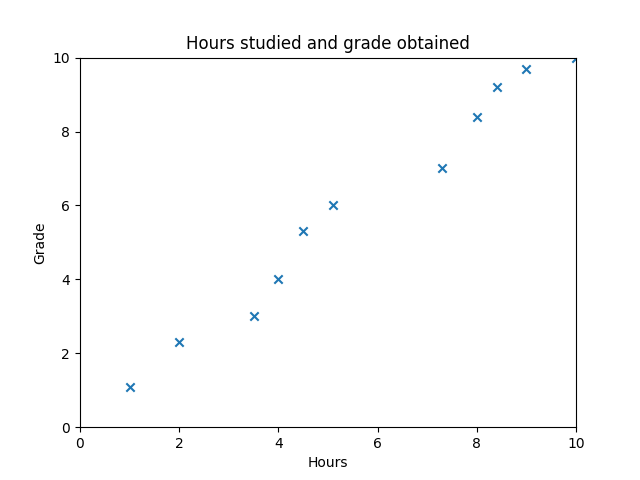
The target of an ML algorithm in this case would be to predict which grade will a student obtain given the amount of hours she has studied. To do so, the algorithm is going to try to find the best parameters for a function so that given a number of hours, its output is the grade the student will probably get. In terms of this example, and being a 2 dimensional problem, the algorithm is trying to find the line that best fits all training examples. In a 3 dimensional problem it would try to find the best hyperplane, etc.
This is better seen with an example:
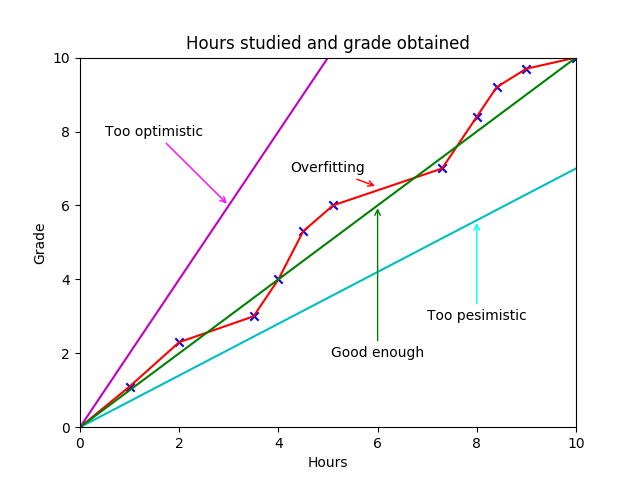
As you can see, there are many possible lines that could potentially predict the grade. A good machine learning algorithm tries to find the best line (function) in order to minimize the prediction error.
It is important to notice that the best line is not the one that better fits our training data. If we adjust too much our function, we risk overfitting (red line in the figure). Overfitting means that our algorithm works super well for our training set but performs very poorly for unseen data. The opposite to overfitting is Underfitting (magenta and cyan lines). This happens when we generalize too much and our algorithm doesn’t work even for our training data. The tricky part is to find a good enough balance (green line). There is always a trade off between the precision you obtain in your training set and the overfitting you are going to have in your algorithm.
Unsupervised learning
When the data is unlabeled, we are in front of an unsupervised learning problem. In unsupervised learning, one usually tries to find patterns in data. The classic example of unsupervised learning is clustering. A clustering algorithm tries to find groups within the data that share similarity. Take as an example the plot below:
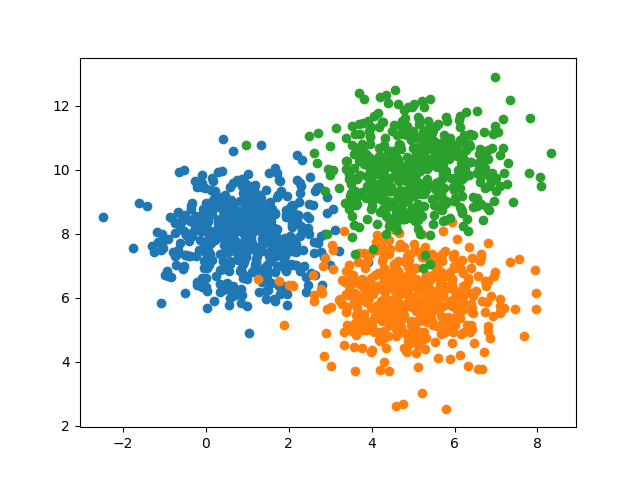
In this case, a human can clearly see three clusters of data, right? The objective of a clustering algorithm is to do so automatically and be able to classify new samples in the corresponding groups.
You can read about some specific implementations of clustering algorithms here.
Unsupervised learning algorithms also suffer from overfitting and underfitting problems.
Neural networks (NN) can be supervised or unsupervised. Though they are more complicated to understand than clustering algorithms (in my humble opinion), the main idea behind a neural network is that information passes through many interconnected processing steps. The number of steps that the algorithm takes is what we call layers in a NN. The name “neural network”, as fancy as it sounds, comes from the idea behind the algorithm, which is inspired in what we know about how neurons in our brain work.
Neural networks are computationally very expensive and thus they have been an object of study only until recent years. Thanks to the increasing computational power, we can now compute tasks that were just impossible before. This has opened up a new world in ML, allowing us to compute neural networks with many layers of depth. This is what we call deep learning nowadays.
That’s it for now
Obviously, there is much more to ML than what I wrote in this post. But that is why there are so many interesting books about the topic. I hope this post can serve as a reference for anyone that wants a quick introduction to the basic concepts of machine learning. If you find it interesting and want to move forward, here are some resources that may be interesting:
- Data science from scratch: Introductory book to the use of machine learning
- Python machine learning: Very detailed book in which you’ll learn the algorithmic details
- Coursera ML course: More dynamic, online course in which you’re learn in detail, and practice, most ML concepts we talked about in this post.
I hope this was useful! As alway, please feel free to comment, and share if you liked it!
NOTE: Here you can find the code I used to generate the plots in this post
